




基本的思想就是递归生成,要严格按照一定步骤,就像解九连环那样,决不能碰运气。
一开始的步骤是这样,如果左下角第一个数字是,那么就在他的右边放
,依次类推,直到剩下4或者2,此时只要往末尾的数字填一个4或者2,顶端数字就会变成
。然后在顶端数字旁边,再用同样的方法构造
,
……直到逐格降幂后出现4或者2。如果最后一行用完了,就转弯绕上来。
下图是一个游戏刚开始的例子,我只要在右下角合并一个2,顶端数字就可以变成32,然后我继续再顶端数字旁构造16、8……

.严格按照这种方法,最后胜利前的图是这样的:

此时只要弄一个8出来和第三行第一列的数字合并即可达成2048。
这种方法要求你绝对慎用向上键。向右键也需要谨慎使用,只有在数列所在行满行的时候才能使用。否则在左下角可能会出现4或者2,这会将你的数列错行。
有一个问题是,这种方法做出来的2048,由于最后一个步骤是将等比数列求和,所以屏幕上几乎不剩任何数字,分数较低。但没关系,这个小游戏刚刚取消了只能玩到2048的限制,只要按照这种方法玩,不仅2048几乎可次次达成,然后再keep going,4096都不是梦(需要运气)。
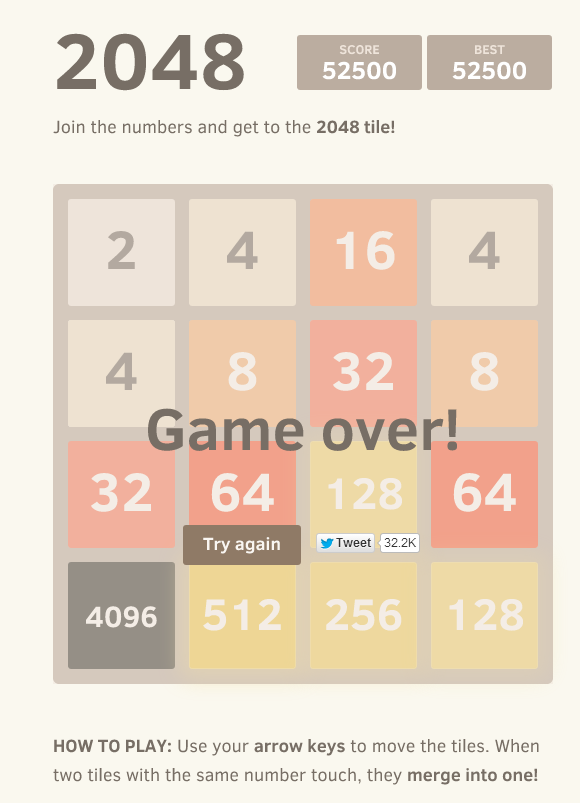
(败在了追寻8192的路上,顶部空间不够了)
重大更新!已突破16384!求对手!上图

实我是来显摆的。作为一个完成8192超10w分的人应该还是有资格回答这个问题的。其实按照数据帝的玩法基本是2048没有问题的了,还有一点就是要固定好所需要的数字,例如最后一行排列着
256 512 1024 2048。这时候你就需要一个256在第三行第一个格,为了保持这个位置,你需要塞满第三行来固定。大概就是这样了。ps:目测极限就是16384了,因为我玩到8192的时候已经差不多没有格子放数字了,上图如此混乱是因为我已经玩到困了...=_=游戏的时候尽量不要向上推,推了就很难控制位置了。
-----------------逼于无奈分割线---------------
这答案好像写得口气有点大了…有不少人说要挑战…但是挑战也走心一点好吗…不要用悔棋版啊啊啊啊…我玩的不是悔棋版啊啊啊啊…你们用悔棋版挑战我的正常版…我也是醉了=_=
5.9update,一点小修改。
个人测试合成2048需要7分钟,4096需要15分钟左右,珍爱生命,远离2048 :)
已经玩了很久,已合成8192,基本每局都能合成4096的来挖个坑,早晨起来就答~
不过我的水准暂时也就是8192,大神们就不要搭理我了,新手们可以看一下嗯。
个人认为这个游戏是比较机械的,有固定的玩法,只要不出差错,2048还是很容易得到的~

第一次觉得有一个问题一定要认真答一下!!毕竟花费了数十小时玩这个!
下面就是我的一点见解。 :)
我认为这个游戏可以分为几个阶段。
1.初期(刚开始一局游戏)
有序性(水准至少是对这游戏已经有所了解)
这个游戏很关键的就是数字的布局要有序。
对于我的游戏习惯而言,就是最大的数字摆在左上角,且尽量不让它移动,左边数第一列的数字,大小顺序就如上图那样,最大的在左上,然后从大到小排布下来。
这样做的意义在于所有的数周围都是大小接近的数字,方便合成更大的数字, 初期的布局就如下图。

2.中期
合成512 1024之后
在合成1024之后,你会发现你的格子有点不够用了!如下图~
目的是让第二列最大的数及时与第一列最小的数合成新的数字,从而节省格子。布局如同上图~
但是很有可能你的布局出现我这样的问题(如上图),第二列最大的数字大于第一列最小的数。此时就会导致第二列最大的数字不方便加入第一列。
此时的解决方法有两种:
1.把64移到上面的位置,然后移动一个2到64和32所夹的格子处,再然后把这个数字不断合成为更大的数字,到了32时就可以让它加入第一列了!然后继续保持这种布局继续完成~
2.可以将错就错,将第二列最大的数字合成到和第一列倒数第二位的数字相同时再加入第一列,比如上图中的64可以进一步做成128再与第一列的128合成更大的数字。
3.中后期
2048之后的玩法(各种小问题及解决)
其实和1024之后的玩法接近,就是要保证布局的稳定性,即第一列和第二列的大小顺序。
我觉得这个阶段最重要的是细节。
每一次向下划的时候都要注意第一列是不是又相同的数字,避免最大的数上面出现一个2.
再比如合成过程中一定要注意出现下图的问题

此时只能向右划了有木有!一划就要出问题有木有!
避免这个问题的核心我觉着就是一定要每一步都思路清晰,要让每个数字附近都是大小接近的数字,当布局不太正常的时候,早早注意到就可以避免,这样就很难出现这种问题了。
万一(其实根本不是万一),最大的数字上出现了一个2,该怎么拯救!

具体来说就是尽量使用向下和向左的操作, 将1024这一行的四个数字做成不一样的(确保不会向右移动),且1024上 的那一行可以向右滑动,此时向右划,空出1024上的位置,向上滑就把1024移动到了左上角,再然后就是调整一下布局,使它有规律,就可以继续操作了。
第二种方法还是将错就错,将上图中的2合成一个8,从而使第一列的数字可以向下再合成一次,这样1024就会出现在第三行,进行上面的操作时会更容易调整。
4.后期
4096以后
个人认为此时的难度主要是格子实在是太不够用了,第一列会塞满很大的数,所以主要依靠第二列,用之前的方法不断往第一列凑较大的数字,同时操作的时候要更加细心,避免出现只能向右划的状况,核心的是第二列也要像第一列一样保持大小布局的稳定性(从下到上的次序为大到小),始终保证最大的在下方,且每次向上划的时候保证这一列不会动。
玩到4096以后就很容易玩死了,所以我也就合成了两次8192,先就想到这么多~如果有需要会再补充嗯,希望有人看到我的答案:)
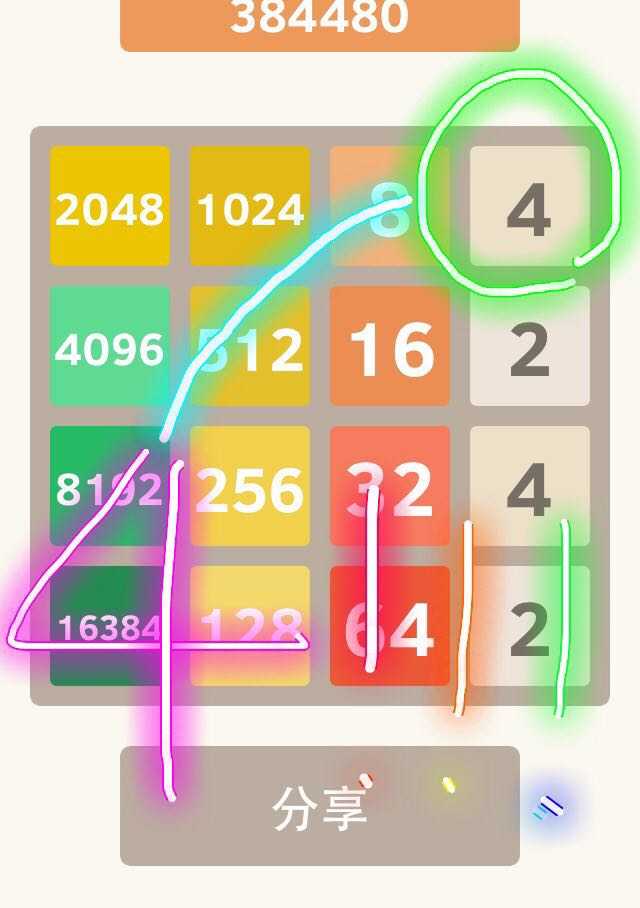
(右上角本可是个2,平凡的2)
我来写一个攻略,帮助各路玩家理顺玩2048的思路。我不准备开口就宣讲怎么才能达到我那么高的水平,那样太轻松、幼稚和不劳而获了。相反,我要以导师的态度向你们传授怎么才能在这款小游戏里走得更远——这并不比练出八块腹肌简单,但也不加难。要知道,咬住痛苦的乳房甘之如饴,人人都能吸出甜美的奶水来。
--------------------
第一章:新手入门
最初的最初,一眼看去方向尚无意义,天高海阔任君去,左右逢源空格多。
(配一张只有两个2的图)
犹犹豫豫开始循着游戏的指引无意识四向瞎滚,随便滚个70-120步后,第一个三位数跃然屏上。
(一个中间有128的图)
再做数百动作,却惊觉已被杂多束住手脚。
(一个512+乱七八糟数字的图)
(大的巨物被小的喽啰蚕食,不得相见;小的鱼虾被大的顽石分隔,无法聚集)
挣扎、扭动、没落。
(一张you died)
(资本的原始积累失败了,游戏在封建末潮的割据混战中落幕/玩一个三体游戏梗)
--------------------
第二章:走出丛林,迎接秩序
又一次站在最初的最初,作为玩家的你却能带着上一轮的惨烈记忆——这是游戏人的幸运。
(一个只有两个2的开局,位置明显不同于图1,最好是贴边缘的并排)
这一次,我们引入简单规则,最大数高踞一角,小数不断向其靠拢。
(一个角落有512的图)
但是,意料之外的情况总是会出现的。(注1)(见文末附录:方法论)
(一个左下角是2,1024在它上面的图)
这意味着简单规则仍有十分不足,其组织太过松散无力。对于这一点需要加以限制。
(一张左下角上数1024、512、256的图)
同样需要注意的是,这种方法的运用十分普遍。最大数列、次大数列乃至有限空间都可以使用。可以避免下图情况出现。(注2) (见文末附录:方法论)
(一张第二列上数2、64、等)
来到游戏的一道门槛前,跨过去、跨过去!
(一张1024、512、256、128、128)
欢迎来到旅途的终点站,请轻度玩家落车并截图留念。
(一张2048)
(一张你赢了2048)
--------------------
第三章:游戏开始
点击继续游戏,思考前路迢迢何以致千里。
(一张左下2048、256等)
大方向既定,且行且审慎。
(一张2048、512等)
似曾相识的一幕出现了,玩家隐隐预见到前路的康庄大道将化为羊肠小径,每一步都如踏在荆棘丛中。
(一张2048、512、256、128、128)
为什么又一次在余三列的空间里造出128?这和达到2048的道路如出一辙。
(一张2048、1024、256、128、128)
规则似乎浮出水面,但被水上的雾气盖住了真正的面容。
(一张2048、1024、512、128、128)
这是一则铁律:以这种学院派的方式游戏,必须千百次踏过同一条、也是最初的门槛:角落里的128与128。然后,一个更高、更大者来到你面前。
(一张2、1、0.5、0.25、0.25)
显然,这是上升到下一个平台所必经的考验——更严苛、更残酷的门槛。你同时也意识到,这不会是你最后一次踏上这道门槛。
(一张4096)
(一张4096胜利)
--------------------
第四章:基础世界观
由于一些误操作,你死了
(一张you died)
(一张4096、1024、256)
仍然循着前述方针走在正确的道路上——但你还是死了,这显然能说明一些问题:方法正确,这游戏就能一直玩下去么?
(两张4096死、一张2048死)
(三张you died)
也许是方法的错?其他探索的路上you died*100
也许是操作的问题?哪怕步步为营算得一清二楚,you died*100
这是个运气游戏,不过如此而已!
但是有人能玩出16384并且觊觎32768的宝座(比如我),有人只能玩个4096就沾沾自喜(比如你,甚至达不到,真菜!)
一定有什么方法可以走得更远?
(一张8192)
(一张8192胜利)
那就是不要死。
只要不死,这个游戏可以玩到的理论极限是131072+65536+32768+16384+8192+4096+2048+1024+512+256+128+64+32+16+8+4
这意味着要每一次产生新数字时都产生4,这是不可控的。
那么,小一级的理论极限是可能的吗?一个65536+32768+16384+8192+4096+2048+1024+512+256+128+64+32+16+8+4+2?
为了说明这个理论极限事实上有多么反人类,我们回到4096的级别上来进行阐述。
(一张4096胜利)
在这段苦难的记忆中,为了达到4096胜利,必须4次踏上2048的门槛。
第一次,是来到2048。
第二次,是在2048的次位造出1024。
第三次,是在1024的次位造出512。
第四次,是在512的次位造出256。
这四次门槛的相同点,在于:除大数列外,余三列的最大位上诞生一个128。
(四张图,分别是上述四种情况的128)
我们将其称为一级门槛,因为这不是唯一的门槛。更高、更大者是你必须克服,而不能是将你克服的障碍。
你必须在余三列的角落诞生一个256。跨国一个二级门槛。
(一张2、1、0.5、0.25、0.25)
聪明的你,完全可以想象到为了达到8192,这个游戏的难度会发生怎样的变化。
首先,在左下角4096的基础上,于次位产生一个1024,一个一级门槛。
(4+0.5+0.25+0.1+0.1)
(4+1)
同理,第三顺位的512和第四顺位的256的生产都需要通过一级门槛。
接下来你发现,为了在左下角4096的基础上,于次位产生一个2048,必须通过二级门槛。
(4+1+0.5+0.25+0.25)
(4+2)
继续推导,第三顺位的1024和第四顺位的512的生产都需要通过二级门槛。
并且,这个过程中还需要走过三次一级门槛。
最后,终于,好不容易,你踏上第三级门槛,来到8192平台。
(8192)
(8192胜利)
欢迎你,堪堪脱离90%的玩家,值得庆贺。
现在我们携手展望一下未来,看看上到下一个16384平台上需要付出一番怎样的努力。

如果从初生玩起,共计需要20个一级(2048级)、10个二级(4096级)、4个三级(8192级)和1个四级(抵达16384)。
再多看一步,如果想走到32768,需要35个一级、20个二级、10个三级、4个四级和1个五级(抵达32768)。
这意味着,如果没有稳定达到4096的水平,需要4个二级才能玩出的8192对你来说希望渺茫。更不须谈10个二级、4个三级和1个四级才能玩出的16384和天一样远的32768了。
假定你有50%的把握玩出4096(二级门槛),那么即便不考虑诸多一级门槛和最终的三级门槛,达到8192的概率也仅仅为(50%)^4=6.25%,这就是这个游戏的惊人之处:每上一个平台,就要面对累加的门槛数,以及它们自相乘带来的微暗概率。
--------------------
第五章:微暗的火
没有被吓退的你(假定这些你存在)玩得吐血,抵达16384,你成为了我的战友。这在外人看来多少有点怪异,因为这似乎不是一款值得玩得吐血的游戏。
(一张16384,你的新目标是32768)
(一张16384胜利)
直到这时,我才有机会把人力能及的终极目标指给你看,因为你站的平台足够高、也就能看得足够远了。
那个目标就是32768。在最远端,火光微暗。
走到这么远,早已压住心底的恐惧,觉得自己无所不能了吧?还记得提到过的小一级理论极限吗?一个65536+32768+16384+8192+4096+2048+1024+512+256+128+64+32+16+8+4+2才是最高峰的腊梅,最远极的安息处。区区32768算什么呢?
32768就是人的极限,我对此不存任何困惑。论证如下:
在先前的游戏中,我们关注的门槛是大数列外余三列空间内生产的最大数——造出128就能踏上2048,为一级门槛;造出256就能踏上4096,为二级门槛;以此类推,只要能在这个位置造出2048(多么有趣的原点),就能推回4096、8192、16384,最终踏上32768。这是末一级门槛,序列为五。
在游戏的进程里,你不免发现,99%的时间不会涉及到跨过门槛。这些时间里你都在和余三列奋斗,力图抵达门槛的边缘。
(一张2048、一张4096、一张8192任意门槛)
而在余三列的时间中,又有半数是在余二列中不断腾挪,用灵活的技巧博升阶。
(一张8+4的余二列,一张8+4+2+1的余二列)
甚至在死亡与死亡之间,你都在对闭塞的余二列空间感到恐惧。
(8+4+2+1余二列阵亡)
(you died)
但是每一次成功来到新平台前,都是滚雪球般的柳暗花明又一村。
(一张8+4+2+1+0.5+0.25……)
因此,终点不在五级门槛,而在余二列的狭小空间里。
要问的问题是这样的:在余二列里,我有把握造出最大的数是多少?
(余二列的128)
答案是128,当初绞尽脑汁爬到2048上的垫脚石又一次出现在这里。不同的是,现在只需要2*4=8个格子就能造出来。
让我们首先把视野聚焦到余二列的2*4方格中。
(空的2*4方格截图)
一个128意味着两个64,一个在角落的64和一个贪吃蛇的64。它的过程当然会是64+32+16+8,于是余二列也被锁死了,现在终极使命是在余一列中的端头处产生一个8。
(64+32+16+8和单列一个8)
这就是终极目标的基石,单列造8。在它之上的单列造16和单列造32分别对应着六级和七级门槛。这两个技巧往简单说——前者几乎做不到,后者几乎不可能。(注4)
着眼于单列造8问题。
当前三列锁死,最后一列的上和下就成了解决这个问题的唯一操作方式。
第一步:一个2移动后会变成两个2共存,与天然的两个2没有任何区别。
(配两个2的图)
第二步:若要在上方造8,务必将两个2向下移动,合并为4,理由很明朗——向上你有1/6概率会暴死,向下则不必面对这一悲惨结局。
(4在底,上贴2)
不能向下动了!只能向上……
(2在顶,贴着4,贴着2)
又不能向上了!只能向下……
(从上到下2242)
向中间合并出8无异于自寻死路,向上合并出8则顺利达成目标。但无论如何都不可能在下端造出8来。反之,若第一个4向上移动,有1/6的概率陷入无法在上端造出8的局面。
(端头的8)
当你达到我的水平,2048只要5分钟不到、8192信手拈来、16384一小时一个的时候,就有能力向32768发起冲锋,避开诸多陷阱(见附录:方法论部分),把手伸向顶端的果实。
独独不能考虑刷出4的情况,是命,不可违。
(you died)
祝你好运!
--------------------
附录:解决局部难题的方法论
注1:最大位松动的解决方案
注2:余三列最大位松动的解决方案
注3:大数列整体移动的解决方案
注4:单列造16和单列造32的不可行性演示
注5:余三列造数小技巧
注6:余二列造数小技巧
注7:一个奇淫巧技
--------------------
后记:
引文以明志
夫夷以近,则游者众;险以远,则至者少。而世之奇伟、瑰怪,非常之观,常在于险远,而人之所罕至焉,故非有志者不能至也。有志矣,不随以止也,然力不足者,亦不能至也。有志与力,而又不随以怠,至于幽暗昏惑而无物以相之,亦不能至也。然力足以至焉,于人为可讥,而在己为有悔;尽吾志也而不能至者,可以无悔矣,其孰能讥之乎?此余之所得也!
为这篇答案创造了诸多生捏硬造的概念,希望读者结合游戏元素自行理解。不另附专业名次表加以一一说明,以免凸显学院派作风降低可读性。
特别鸣谢天底下最可爱的包仔的热情督促,使我聚集起来作文动力,不至于流产难产而死,终于写成。给你肚肚!
如果不经常在国内,希望可以用一个合理的价格,得到较好的治疗,建议可以在国内选择一个成熟的隐形矫正医生。如果不是从小生长在国外,想在国外找到一个好医生是比较难的。见过不少在国外花了昂贵价格做的牙,结果出现不少问题,回国后寻求治疗的。接下来会详细解说,内容较多,希望可以耐心看完哦!
那么距离的远近是否会影响牙齿矫正的效果呢?答案是并不一定,是否有影响取决于以下几点:
1、 牙套类型
2、 良好配合并及时沟通
3、 医生方案设计
一、牙套类型
牙套分为两大类,一种是传统固定牙套,一种是隐形牙套。两种牙套的复诊都有什么特点?哪种更适合远程复诊呢?
传统固定牙套是粘在牙齿上的牙套,无法自行摘取。摘下来的那一刻就意味着矫正已经结束。像常见的钢牙套、半隐形牙套及舌侧矫正都属于传统固定牙套。传统固定牙套的复诊特点:需要每隔4~6周来医院复诊加力。而且在矫正期间会常出现托槽脱落、钢丝扎嘴等现象,都需要及时来医院进行处理。所以,如果带着传统固定牙套,想在矫正没有结束前离开当地,又希望牙齿可以按时理想移动是不能实现的。这时大家会问,那换一个地方再找一位医生,继续治疗不就行吗?对于这个问题,答案当然是可以的。不过大部分的可能,就需要将嘴里的牙套全部拆掉,重新设计方案,重新戴牙套,重新交费。也许大家不能理解,为什么需要如此折腾。因为每位正畸医生对同一个案例会有不一样的理解和方案,出于对患者的认真负责,是很难在半途中接收一个在其他地方做矫正的患者继续复诊的。
而隐形牙套是完全透明、可以自行摘戴的牙套,一般会有几十付牙套,牙套数量根据每个人的难易程度而定。隐形牙套会有一个3D模拟动画,是需要经过医生的反复的设计修改才能实现牙齿移动的效果。而牙套就是根据3D方案一步一步的的生产出牙套的。
 隐适美的3D方案https://www.zhihu.com/video/1079697932508278784
隐适美的3D方案https://www.zhihu.com/video/1079697932508278784患者根据医嘱按顺序,按时间一付一付的佩戴牙套,牙齿就会一点点的移动。只要医生方案设计好,患者配合程度也很好的情况下,牙齿移动与3D方案的匹配程度高达90%以上。隐形牙套的复诊频率也不像固定牙套那么频繁,一般在本地的患者是建议1.5~2个月的时间来医院复诊一次,最长复诊时间可以延长6个月~12个月之久。那带隐形牙套期间也会出现一些小问题的,最常见的小插曲就是把牙套丢失。如果只是丢了一副或者两幅对整体的矫正是没有什么大影响的,但是全丢了就没有牙套可带了,就需要联系你的医生如何处理了。所以,戴隐形牙套对患者有较高的要求。
二、及时沟通交流
及时的沟通交流是可以避免和解决很多问题的,无论是否是外地患者,这个环节也是不容忽视的。沟通交流贯穿整个矫正治疗过程,从开始咨询牙齿矫正开始,到牙齿矫正治疗结束,都需要一个良好的医患沟通。我们从三个时间段开始说:
1、 准备做矫正时
需要告诉你的医生你离开的时间及下次回国的时间,让医生有足够的时间设计方案、生产牙套及进行操作治疗。
2、 戴牙套期间
一般建议在外地的患者最好1~2个月以照片或者视频的方式与医生进行复诊,如果发现牙套有戴的不好的情况时,医生会给予建议。如果出现牙套丢失的情况,也需要及时与医生进行联系。
3、 回国前
回国前提前和自己的医生联系一下,方便预约一个来医院复诊的时间。并且告诉医生这次停留的时间,走的时间等,方便医生为你安排下次离开时的牙套。
三、医生的方案设计
这块是患者无法控制的一个环节,但是却可以进行选择的。当你准备要出国留学,想要做矫正,在咨询矫正时就可以选择一擅长做隐形矫正的医生,如果这个医生刚好有几个外地患者就更好了。
所以,建议大家在准备戴牙套前需要将一些不确定因素想进去,如果不能保证自己在未来的不会有生活上的变动,又想戴牙套的话,可以考虑隐形牙套,并且选择一个有经验的牙齿矫正医生哦!
四、案例分享时间
这个小姑娘是在澳大利亚留学,在出国前想把牙齿矫正一下,因为国外费用比较高。她平均每年能回国2~3次,每次在国内停留20天~2个月时间,希望在这次出国前能带上牙套。从她正式开始确认做隐形牙套开始一直到她带上牙套出国,我从修改方案到牙套生产一共花费了2个月的时间,期间她进行了拔两颗上颌埋伏智齿,做了洗牙补牙,在她出国前两周顺利带上牙套。她整个矫正治疗时间历时2年零9个月,一共做了3套牙套,回国复诊次数是8次,矫正后的整体效果都非常的好!


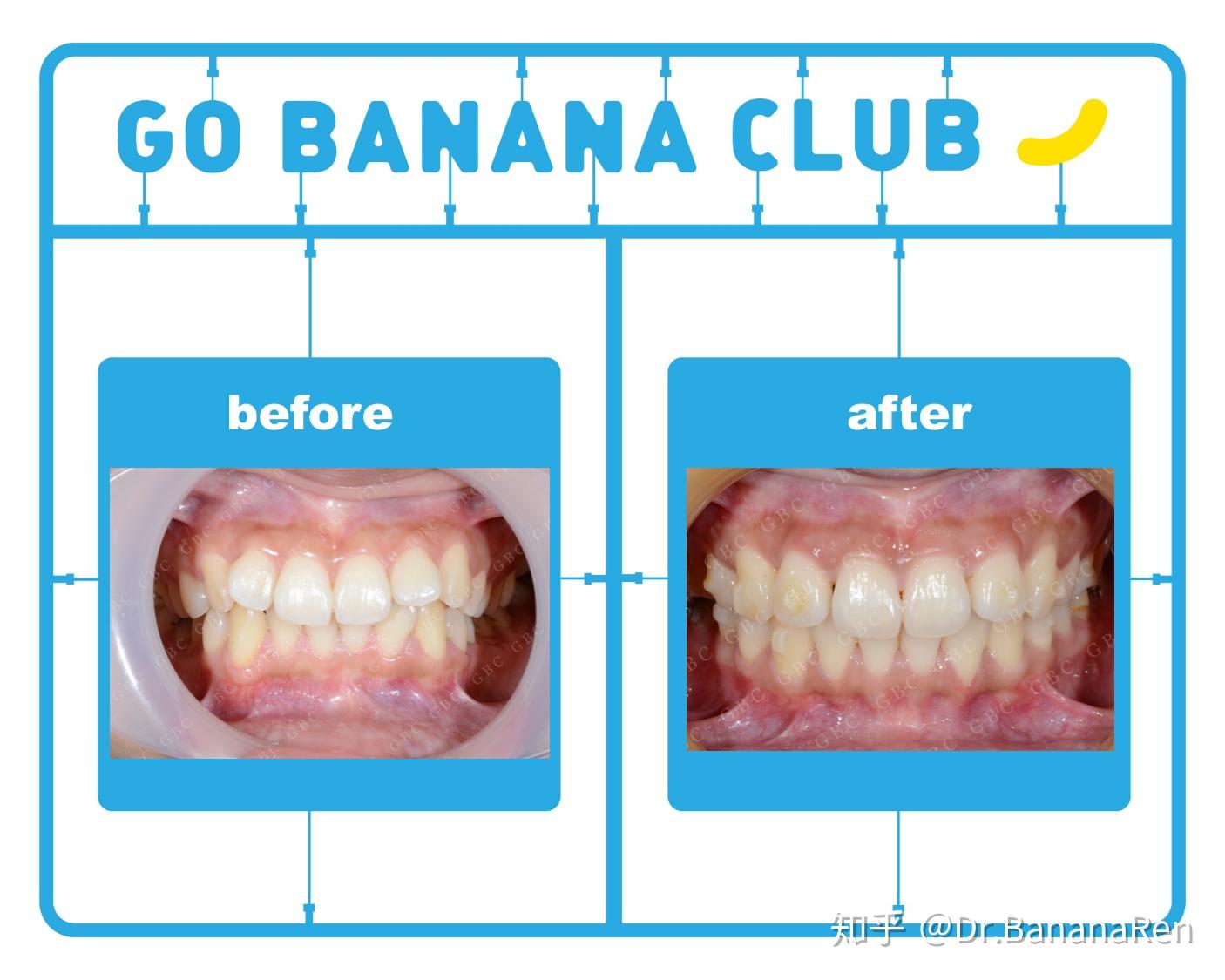
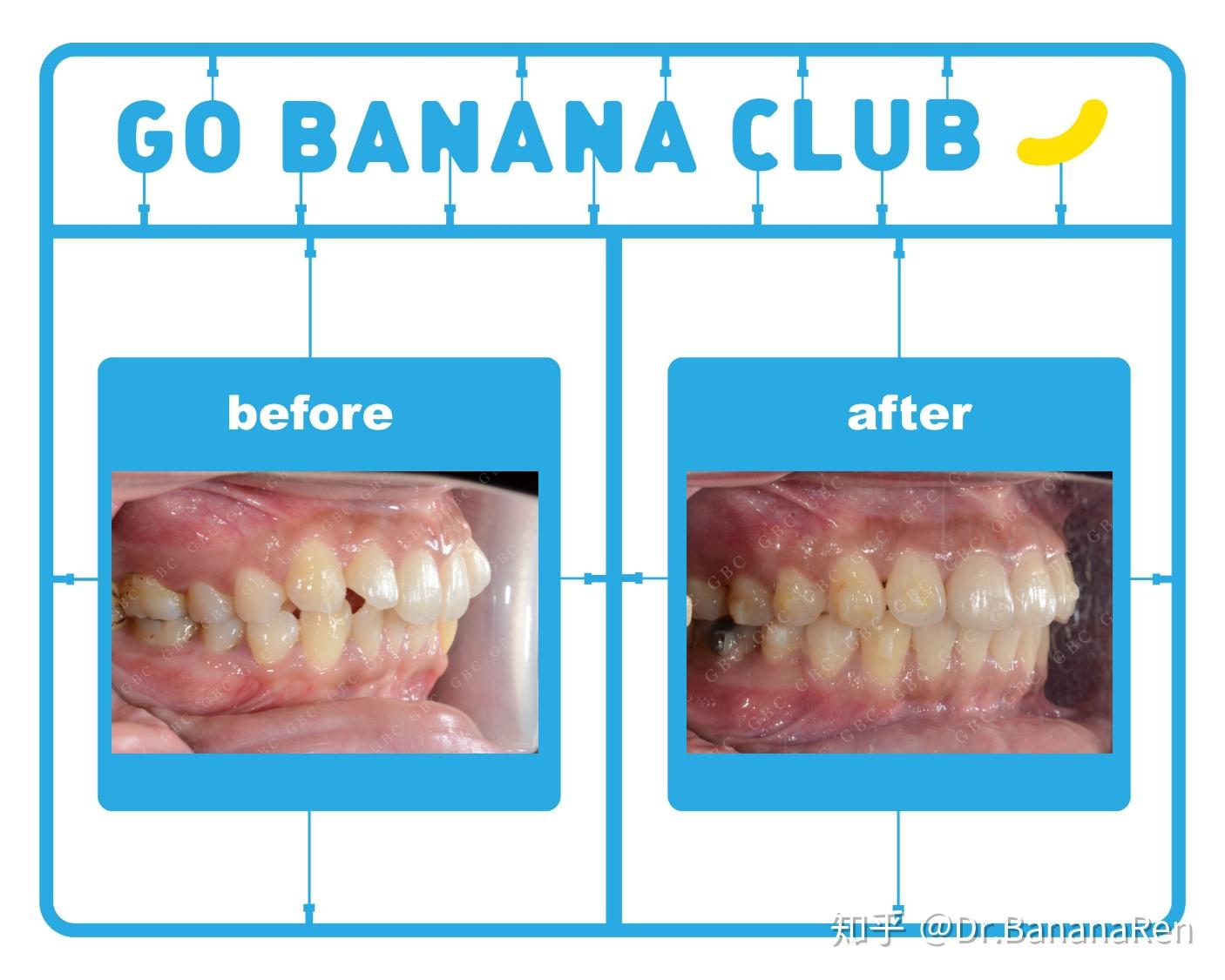
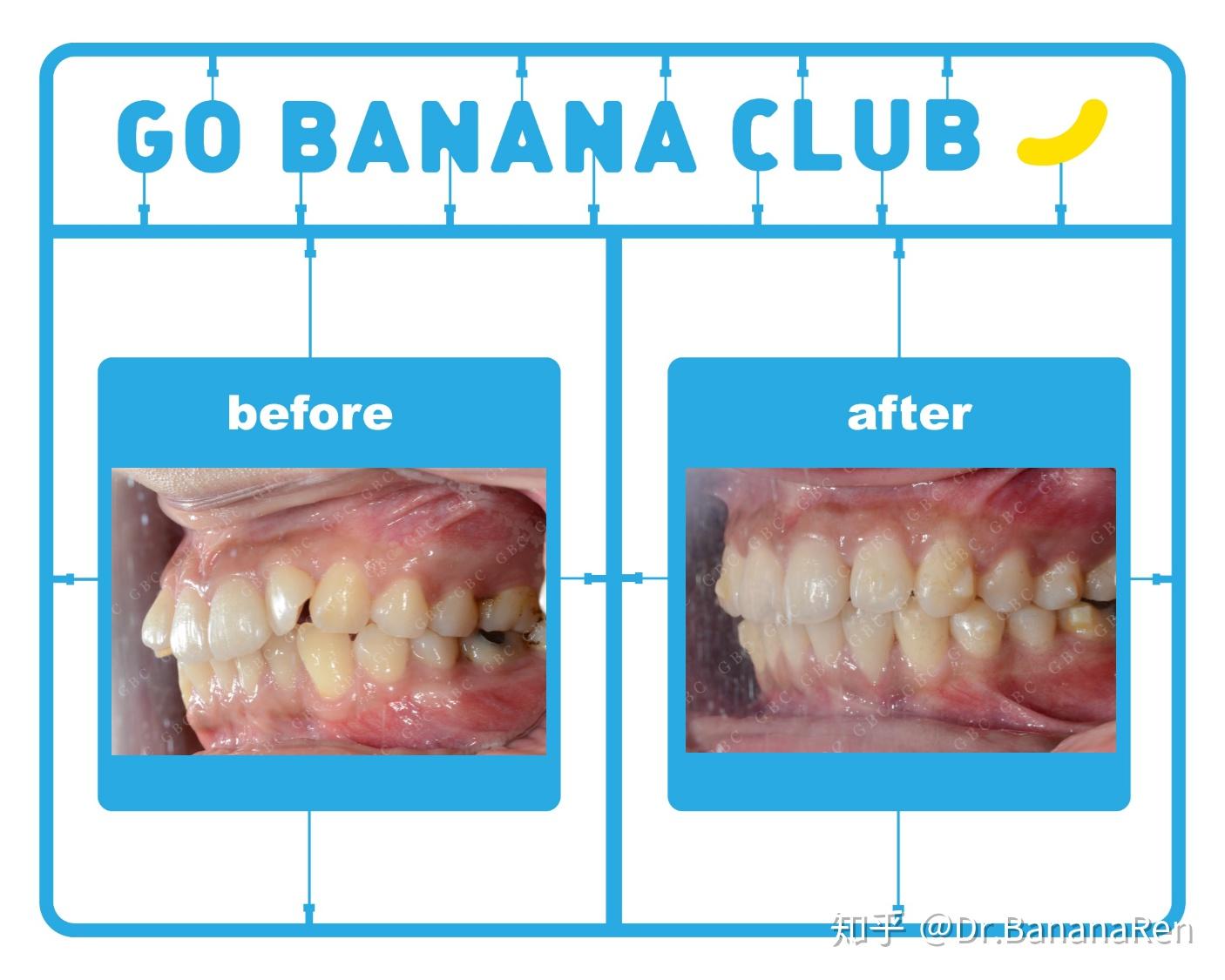
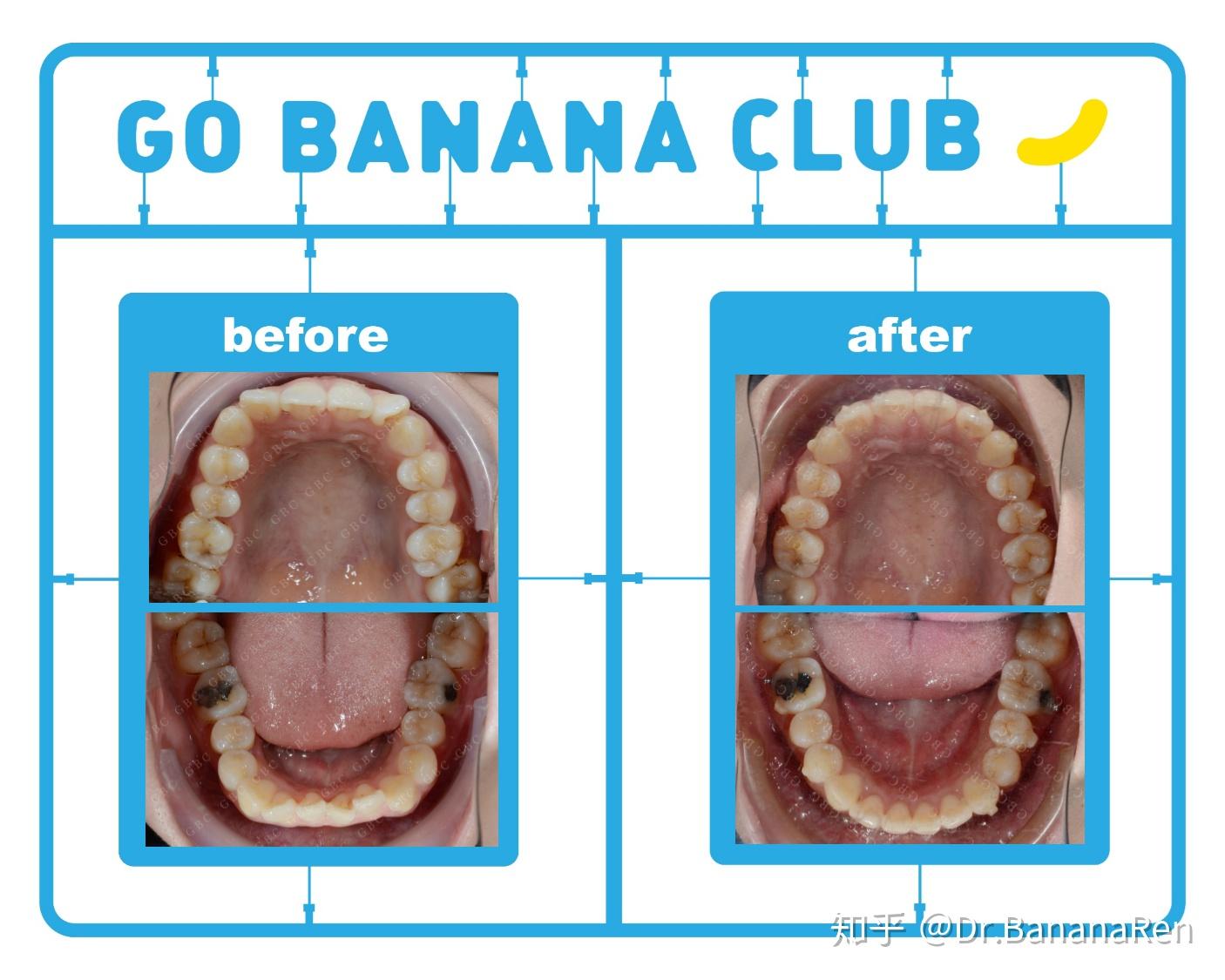
所以,建议大家在准备戴牙套前需要将一些不确定因素想进去,如果不能保证自己在未来的不会有生活上的变动,又想戴牙套的话,可以考虑隐形牙套,并且选择一个有经验的牙齿矫正医生哦!

这个方向理论和实践联系比较紧密,比如,近日RecSys 2020官网公布了本届最佳长短文论文奖,来自腾讯PCG团队的四位作者Hongyan Tang、Junning Liu、Ming Zhao、Xudong Gong凭借研究出一种新的多任务学习个性化推荐模型获得了最佳长论文奖,获奖论文:《Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations》,本人做推荐算法相关工作的,最近也上线了多目标相关的模型,而且还在不断地迭代优化,总的来说,这个方向值得研究,但是肯定也没必要将所有精力放在上面。
坐标深圳:你的信用卡额度这么高,资质很不错,建议不要使用信用卡,因为信用卡利率高达15%以上,如果自己有好的单位,有代发收入和公积金,建议做一笔信贷,去覆盖这些信用卡,合理规避债务,减少自己每月还款压力
流量调控业务就是通过算法/策略/系统的设计和优化,构建平衡平台利益和长期价值的流量分发系统。
代表产品:抖音、小红书、头条
给新内容流量倾斜的目的如下:
目的1:促进发布,增大内容池
- 新内容获得的曝光越多,作者创作积极性越高。
- 反映在发布渗透率、人均发布量。
目的2:挖掘优质内容
- 做探索,让每篇新内容都能获得足够曝光。
- 挖掘的能力反映在高热内容占比。
代表产品:淘宝、天猫、京东、拼多多
- 满足特定商家的营销诉求,实现平台的经营意志,促进平台商家健康活跃发展,提升平台用户和商家价值
- 辅助BD、商业化
- 以流量调控技术为手段,达到低成本撬动商家优质货品资源、提供行业控比的目标,从而提高平台对于供应链的掌控力度。
- 模式:平台与商家签订协议,用流量换取商家的一揽子资源投入(广告费、价格折扣、优质货品独家渠道等),实现平台、商家、用户三方共赢。
- 流量绝对值调控能力,是辅助C2M商业模式的重要手段。e.g. 大促提前备货。
- 平衡平台的短期、长期收益
流量调控业务就是通过算法/策略/系统的设计和优化,构建考虑平台意志和长期价值的流量分发系统。
类似于国家的宏观经济调控,是一只“看得见的手”。
- 在推荐链路中,干涉召回、重排等环节
- 在指定时间段内,提升指定商品集合的某种行为类型次数绝对值,如: 曝光pv绝对值、点击量绝对值
- 【加权、强插】提升物品集合的pv相对值
- 优点:容易实现,投入产出比好
- 缺点:
- 曝光量对提取系数很敏感
- 很难精确控制曝光量,容易过度曝光和不充分曝光
- 【保量】提升商品集合的pv绝对值/click绝对值
- 如:排序位置调整
- 难点
- 线上环境变化后,需要重新调整模型/提权系数
- 新增召回通道、升级排序模型、改变重排打算规则……
【思考】给目标内容boost越多越有利?
- 好处:排序位置 提升越多,曝光次数越多
- 坏处:【拔苗助长、物极必反】把目标内容推荐给不太合适的受众
- 点击率、点赞率等指标会偏低
- 长期会受推荐系统打压,难以成长为热门内容
- 建议:进行差异化保量
- 基础保量:普通内容
- 差异化保量:优质内容、优质作者
- 需要一个质量分评估模型:如:商品人气分模型
- 作者侧指标(反映作者的发布积极性)
- 发布渗透率=当日发布人数/日活人数
- 人均发布量=当日发布内容数/日活人数
2. 用户侧指标
- 调控内容指标:调控内容的点击率、交互率等
- 大盘指标:消费时长、日活、月活
3. 内容侧指标
- 高热内容占比(衡量系统挖掘优质内容的能力)
- 调控目标达成度
【思考】大力扶持低曝光新内容会发生什么?
- 作者侧发布指标变好
- 用户侧大盘消费指标变差
- 支持两种调控类型
- 保量:规定时间段内,单位时间(如,每天)的流量至少为设定值,实际流量可以超过设定值
- 逼近:规定时间段内,单位时间(如,每天)的流量逼近设定值,不会大幅超过设定值
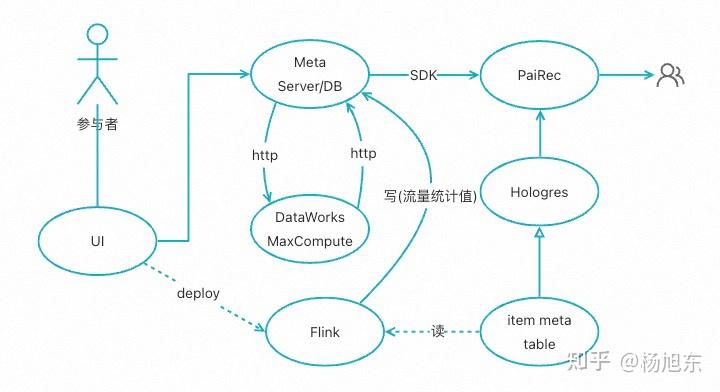
【PaiRec】调控算法需要三个输入:
- item属于哪些调控计划
- 每个调控计划目前为止的累计流量(占比)
- 每个调控计划当前时刻的设定目标
对于第一个输入(item属于哪些调控计划):
- 调用SDK,从Meta Server获取所有在线的调控计划及目标的meta信息;
- 查询Hologres,获取item的属性数据;
- 遍历调控计划,根据调控计划的物品筛选条件以及item属性判断物品从属的调控计划集合;
对于第二个输入(每个调控计划目前为止的累计流量/占比)
- 调用SDK,获取每个计划 (或计划内物品) 的累计流量;
- 若调控目标为流量占比,同时通过SDK从DB中获取“限制物品集”的整体累计流量,计算流量占比;
- 各计划的实时累计流量为flink任务通过http服务实时写入DB
- flink job通过http服务获取当前在线调控计划的meta信息;
- 通过调控计划的meta信息判断item属于哪些调控计划;
- 统计每个调控计划当天到目前为止的累计流量,并通过http服务写入DB
对于对三个输入(每个调控计划当前时刻的设定目标)
- 对于调控目标为流量占比的计划,每个时刻的目标记为设定的目标(daily or hourly)
- 其他类型的调控目标,在MaxCompute上做好计划的小时级/30分钟级流量预估,并等比例设定每个时刻的调控目标
- DataWorks上获取调控计划meta信息;设定目标;通过http服务更新到meta server
流量调控算法有很多,这里仅介绍一种最重用的‘PID调控算法’。其他调控算法请见下回分解。
PID 是比例(P)、积分(I)、微分(D) 控制算法,是一种基于反馈控制原理的控制算法,用于控制和调节系统的输出。 它的基本原理是通过比较系统的实际输出与期望输出之间的误差,根据控制算法计算出相应的控制量,从而调节系统输出。 它可以有效地控制系统的输出,使其朝着指定的期望输出进行调节。
PID 控制算法的主要步骤如下:先计算系统的误差,然后根据控制算法计算出相应的控制量,最后将控制量应用到系统中,从而改变系统的输出,使其朝着期望输出进行调节。
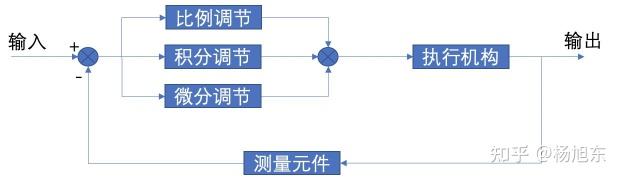
PID算法在 时刻的输出为:
其中,为比例增益;
为积分时间常数;
为微分时间常数;
为控制量(控制器输出);
为被控量与给定值的偏差。
为了便于实现,需要将上式变成差分方程。假设 为采样周期,
为采样序号,我们作如下近似:
将近似表达式代入PID公式,得
其中,积分系数: 可以用
表示; 微分系数:
可以用
表示;
这样PID公式可以改写为:
PID 控制算法的三个参数(,
和
)的变化可以改变系统的控制性能。
参数控制系统的响应速度,能迅速反映误差,从而减小误差,但比例控制不能消除稳态误差,
参数控制系统的抗扰性,只要系统存在误差,积分控制作用就不断地积累,输出控制量以消除误差。因此只要有足够的时间,积分控制将能完全消除误差,但是积分作用太强会使系统超调加大,甚至使系统出现振荡;
参数控制系统的稳定性,可以减小超调量,克服振荡,使系统的稳定性提高,同时加快系统的动态响应速度,减小调整时间,从而改善系统的动态性能。
PID算法的调参方法请参考:《 流量调控PID算法调参指南 》。
任何流量调控算法或策略或多或少都会对大盘的短期业务指标造成一定的负面影响(除非推荐算法本身还有很大的提升空间)。 这里我们假设原有的推荐算法是一个完美的算法,它推出的物品集合以及物品之间的排序都是最优的,任何变动都会造成短期业务指标的下跌。
PID算法只能保证调控目标的达成,但本身并没有办法把对大盘业务指标的负面影响控制在一定范围内。 因此,在PID算法之上还需要加入各种流量平滑的策略和机制,来尽可能减少调控带来的负面影响。
我们采用的流量平滑策略包括但不限于:
- 个性化调控。根据用户对调控物品的偏好程度调控,尽可能把调控流量分配给确实需要的用户。
- 动态调控目标。渐进式达成全天的目标,在时间上平滑。根据预估流量,非线性地设置每个时刻的调控目标。
- 打散约束。每个请求仅能承载有限数量的调控上提物品,并且曝光位置不能过于集中。
为了使得PID算法的调参经验能够更好地在不同场景间迁移,我们没有采用常规的对排序分进行加权/降权的方式,而是采用了直接调整排序位置的策略。
假设展示位置调整量为 ,那么
- sort by
(可能是负值)
的计算公式如下:
其中, 对应一个调控目标;
对应一个item;
是item
的模型得分;
是得分最高的item的模型分;
是按照模型分降序排列得到的rank位置;
的PID算法输出的调控信号;
是调控目标
的权重,反应当前用户对当前调控目标商品合集的总体偏好程度,其计算公式如下:
最终的调控位置偏移值的计算:

阿里云计算平台PaiRec团队为对推荐场景下的流量调控需求打造了一套通用的解决方案。
流量调控产品的用户手册请查看 《 流量调控用户手册 》。
有任务问题请随时联系我们!感谢您的支持!
放牛的星星:《原神》主机版渲染技术要点和解决方案你猜牛佬在知乎上被人追着骂了几条街?
对于7*24小时不间断运行的后台服务,监控告警是稳定性运行的基石。很多开发者都有过这样的经历,对服务的每一个指标都做了严格的监控和告警,唯恐漏掉告警导致问题无法发现,导致每天接收到大量的无效告警,告警的泛滥逐渐麻痹了警惕性,结果真实的问题初漏端倪时却被忽略,最终导致了严重的故障。
如何提升告警的有效性,准确识别问题,同时又不至于淹没在大量的无效告警中,正是本文所探讨的内容。
首先来看一下告警的重要性,为什么我们需要耗费这么多精力来优化告警。虽然我们都期望一个服务是没有故障的,但事实确是不存在 100% 没问题的系统,我们只能不断提升服务的可靠性,我们期望做到:
- 对服务当前状态了如指掌,尽在掌控
- 能够第一时间发现问题,并且快速定位问题原因
要想做到以上两点,只能依赖完善的监控&告警,监控展示服务的完整运行状态,但是不可能一直盯屏观察,并且也不可能关注到所有方面,要想被动的了解系统状态,唯有通过告警,自动检测异常情况。
所以,告警是团队监控服务质量和可用性的一个最主要手段。系统故障相关的时间问题通常用MTBF、MTTF、MTTR这三项指标来表示。
- MTTF (Mean Time To Failure,平均无故障时间):指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。MTTF=∑T1 / N
- MTTR (Mean Time To Repair,平均修复时间):指系统从发生故障到维修结束之间的时间段的平均值。MTTR=∑(T2+T3) / N
- MTBF (Mean Time Between Failure,平均失效间隔):指系统两次故障发生时间之间的时间段的平均值。MTBF=∑(T2+T3+T1) / N

可靠性在于追求更高的MTTF和低的MTTR(平均无故障时间)。最好的情况是能够不产生故障,但不存在100%可靠的系统,当出现故障/异常时,我们需要尽可能减少MTTR(平均修复时间),告警的意义在于尽可能减少T2 + T3时间。
理想中的告警,不存在误报(即本来正常的,告警为异常)也不存在漏报(即本来异常的,误认为正常),所以理想的模型满足以下三点:
- 误报为0:出现的告警都是需要处理的问题
- 漏报为0:异常问题都能够告警发现
- 及时发现:能够第一时间发现问题,甚至于在导致故障前发现问题
但在实践中无法做到理想情况。要减少漏报,需要针对每一种可能发生的场景进行监控,同时配置告警,这其实并不算困难;但我们的告警往往不是太少了,而是太多了,以至于需要耗费大量时间处理无效告警,由于告警过多,容易忽略真正有用的告警,导致异常发现的时间变长,或者忽略的潜在的风险。所以对于告警,最大的问题在于如何减少无效告警,提升告警的效率。
先来看一下无效告警产生的原因。
监控系统应该解决两个问题:什么东西出故障了,以及为什么会出故障。其中“什么东西出故障了”即为现象,“为什么”则代表了原因(可能是中间原因)。现象和原因的区分是构建信噪比高的监控系统时最重要的概念。
在实践中,想绝对做到这两点几乎不可能,但我们可以无限趋向于理想模型。
告警一般是通过“现象”来判断,而是否有问题要看产生现象的原因判断。相同的现象引起的原因可能不同,这种“可能性”是导致误告警的最核心原因。

举个例子,请求失败告警,原因可能是请求内容有问题,也可能上游机器异常,或者是我们自身的服务处理异常。理想的情况肯定是期望告警有着唯一的原因,但实际上由于现实的复杂性,未必能够做到精准的区分。

减少误告警的思路,就是要尽可能减少现象产生的原因,如果能减少到唯一的一个原因,那就能很明确问题所在。
同样是告警,对于CPU跑满这种情况需要立即处理,但对于单机健康状态告警(正常异常机器会自动置换,异常情况可能置换失败),系统并不能自动解决这种状况,但是一段时间内不处理,也不会造成影响,负载均衡设备会自动摘除。
所以这里涉及到一个告警分类的问题,当然,告警可以有很多种分类方法,分成很多种级别区别对待,但在优化无效告警的目标下,我们通过是否需要立即停下手头工作立即处理,分为三类:
- 紧急:收到报警就需要立即执行某种操作。如CPU跑满,内存跑满等。判断标准,是否对业务有影响,以及是否有潜在的未知风险
- 不紧急:系统并不能自动解决目前状况,但是一段时间内不处理,也不会造成影响。如单机出现访问不通异常。判断标准,对业务无影响,基本无潜在的风险,但最终需要人工介入处理
- 不需要处理:已知异常并且系统会自动恢复,不需要人工接入。如机器虽然出现异常,但运维底座会再一段时间内自动处理,不需要人工介入
对于一个异常,首先需要判断是否需要立即处理,区分进行优化。
对于不需要处理的异常,则完全没有必要进行告警。如果需要感知事件,可以通过邮件方式进行时候定时通知,无需通过告警渠道打断工作。
对于不紧急的告警,如果工具支持的话,应该以工单的形式定时推送,统一处理,没必要进行实时告警,减少对正常工作的打断。在工具不支持的场景,可以适当调整告警间隔时间,以及重复告警的收敛策略。如单机异常可以整点告警,避免重复打断工作,当然,如果同时超过一定百分比的机器异常,这便转换为紧急告警了,需要实时触达。
对于紧急告警,应该尽量提升其实时性和准确性,尽可能去除无效告警。那应该如何进行无效告警的识别和判断呢,接下来可以看一下告警设置的原则。
每当告警发生时,值班同学需要暂停手头工作,查看告警。这种中断非常影响工作效率,增加研发成本,特别对正在开发调试的同学,影响很严重。所以,每当我们收到告警时,我们希望它能真实的反映出异常,即告警尽可能不误报(对正常状态报警);每当有异常产生时,报警应该及时发出来,即告警不能漏报(错过报警)。误报和漏报总是一对矛盾的指标。
以下是一些告警设置原则:
- 告警具备真实性:告警必须反馈某个真实存在的现象,展示你的服务正在出现的问题或即将出现的问题
- 告警表述详细:从内容上,告警要近可能详细的描述现象,比如服务器在某个时间点具体发生了什么异常
- 告警具备可操作性:每当收到告警时,一般需要做出某些操作,对于某些无须做出操作的告警,最好取消。当且仅当需要做某种操作时,才需要通知
- 新告警使用保守阈值:在配置告警之初,应尽可能扩大监控告警覆盖面,选取保守的阈值,尽可能避免漏报。
- 告警持续优化:后续持续对告警进行统计分析,对误报的告警,通过屏蔽、简化、阈值调整、更精准的体现原因等多种方式减少误报,这是一个相对长期的过程。
再以请求失败举例,如仅当请求的失败量超过某一阈值时告警,可能存在多种原因,如一些恶意构造的请求,也触发失败量告警。这样的告警既不具备真实性,也不具备可操作性,因为确实无需任何处理。对于此类情况,我们应该尽可能通过特性加以识别,从而更加精准的区分原因的告警。
另外优化告警的一个必备条件,就是要熟悉所用告警平台使用,如果都不知道告警平台可以做到什么程度,可以设置怎样灵活的条件阈值,是很难对告警做合理优化的。
- 监控告警平台能做到什么:业务基础指标,系统基础指标,各种维度的统计方式
- 告警阈值设置:如何电话/短信告警设置
- 告警统计和趋势:有利于进行数据分析和优化告警
以请求失败举例,告警平台是否可以区分不同原因类型告警,是否可以统计成功率告警,是否可以配置持续多久告警,是否可以配置环比同比条件告警;以及不同类型的阈值区分配置,不同条件下的短信,还是电话告警,短信一段时间未处理是否可以转换为电话通知,是否可以屏蔽重复告警等等。所有的特性都有利于我们设置一个精准的告警条件。
另外平台提供的统计和趋势,有利于我们进行针对性优化,查看每天每周的TopN告警是什么,整体的趋势是什么样的,从而进行针对性优化。

前面提到了告警的优化是一个持续的过程,不存在一劳永逸的事情。需要每天或者每周安排值班人员负责告警事宜,这点上确实是需要一定的投入。值班同学需要持续关注告警的有效性,对于出现的无效告警,分析清楚原因,持续优化阈值或者告警策略。
合理的告警流转流程:

处理流程中,在告警触发后,通过短信/电话等方式触达,值班处理人接单处理,再接单后处理完成前,重复的问题不再触发告警,以避免大量的重复无效告警。确认原因后结单返回原因。
可能受限于告警工具问题,不能严格的按照流程来推进(比如一次异常事件,由于告警平台不支持,处理过程中可能触发很多重复告警;系统没有反馈原因的流程等),但是值班同学心里需要有这样的流程,确保每条告警都是清清楚楚在哪个阶段,没有含糊其辞之处。
另外值班同学要强调几点注意事项
- 确保能够收到所有告警:可以通过接收人组解决,确保所有值班同学都在一个接收人组,如果有人员变动也方便修改
- 上升线路:需要判断问题的严重性,适合时机上升,增加资源快速把问题消灭再萌芽状态
- 明确根本原因:确保弄清楚问题原因,而不是表面上恢复。比如单台机器CPU跑满告警,可能存在未知的死循环问题,如果仅仅重启进程恢复,很可能掩盖了问题,导致未来出现大面积的死循环引发故障
最后告警的处理,在心态上要做到:凡事最好能在不疑处有疑,不能在有疑处不疑。
- 《SRC:Google运维解密》
- 《MTTR/MTTF/MTBF图解》:https://blog.csdn.net/starshinning975/article/details/102893787
- 《一篇文章了解监控告警》:https://zhuanlan.zhihu.com/p/60416209
- 《准确率、精度和召回率》:https://www.cnblogs.com/xuexuefirst/p/8858274.html
- 《告警配置的一些原则和经验》http://wsfdl.com/devops/2018/02/07/configure_alarm.html
在树木上可以代替近处高精度实时shadowmap从而减少大量渲染开销

我发现有句俗话很适合shadowmap,就是早晚要死。早上或傍晚,因为太阳角度的关系,会导致一个渲染点附近很远距离的低矮物件都可能投影到它,导致需要投影的对象特别多。而且因为覆盖范围大所以深度图的精度会严重下降。


手上项目被反馈远处启动staticshadowmap时,房檐的阴影会丢失。我测量了下房檐大概0.25米。我在4x4公里大场景采用的是 200米拍2048的离线shadowmap,但因为新图太阳很倾斜,导致灯光相机farclip接近了1公里。
我验证了下 从左到右分别是1米 0.5米 0.25米的cube,果然在0.25米就阴影丢失。

这是因为,离线shadowmap 数据量很大,没采用float16来存储。而是用了50%大小的 RG Compressed BC5存储。这样能存的精度就不是1/(255*255)了,而是1/(255*sqrt(255)) 为1/4096了。因为灯光相机跨度1000米 又因平行光 灯光相机是正交的,所以深度是线性的。也就是1米有4个单位存储。所以0.25米就区分不清了。
我第一反应是不要存灯光方向的深度,存地表平面的高度,因为大部分都是贴合地表的 不会离地表太高。然后根据线性映射关系可以求出对应到灯光相机的深度。但是没想太清楚如何实现。然后照例去图形群求教经验,被告知GPU精粹有分段式处理。又有好心人告诉了更具体的PSSM。但是我看了下PSSM这个是做实时的根据距离 做不同精度的分割,我离线数据是无距离概念一次性存入等精度的。而GPU精粹 这系列武林绝学 太多本了 没信心能找到。最主要的是之前的想法 结合听到 分割关键字。脑子里其实立刻有了可行的算法了。
如下图所示 整个灯光相机空间 farclip-nearclip 跨度是很大的。但是 那些远离地表的高空部分 大部分都是浪费掉的。那里没有静态物体需要投影。我们可以根据X轴(画面的左右方向)坐标,给出一个不同的偏移,让深度值 值记录这个范围内的。这样覆盖的深度少,精度就提升了。学过微积分的都能又想到只要切割的无限细。就是下图的红线部分。直观的一句话就是 在深度值越大的地方也减去一个越大的基准偏移。让深度值在原本[0,1],变成在[0,a],a明显小于1。


可以看出这个方案虽然看上去很有道理 ,但只能提升3倍左右精度,经过测试不太满意,而且偏移的计算比较复杂我没信心解释清楚。所以就放弃这个方案了。
我需要更高精度的方案,比如这里farclip为600,物体离地表大约40米(大多数树木和建筑的最高高度).那么我希望获得15倍精度。就是只记录高度信息。如下图表示 b点不存 灰色的深度值,而存储hb的值,就是这个值的范围 就是40米内。比深度范围600小很多。当我们要渲染a时。根据灯光相机uv计算 可以找到 b点的灰色线,常规是用a点到相机平面距离与b点到相机平面距离做大小判定的,但我们存的是hb,光线方向又固定,所以只要判定a点到红线的距离与b点到红线的距离即可知道是否被遮挡。当然如何红线很高。这个方法就没意义了。实际的精度也没600/40 15倍这么多,因为深度图变化很多对应的高度图才变化一点点,所以等于对精度要求更高了。但在这个数据下还是有提升的 如下效果图为证。


投影shader关键代码

阴影采样对比代码

类似方案1,但更好实现些,不那么绕,就是先用float32 格式来绘制一个高精度shadowmap,然后把他划分成nxn块,用computeshader 统计每一块的 最大深度最小深度。然后每一块的 (深度-最小深度)/(最大深度-最小深度) 裁剪映射到【0,1】区间。每块的最小值 最大值 存储成buffer 渲染时 还原出真实深度再对比。
效果更稳定些 几乎每个0.125m的cube都有投影。

c# 关键代码 创建2个精度RT然后 调用computeshader来 分块复制,并创建 每块深度偏移的buffer数据

computeshader代码,因为离线生成所以不用太考虑性能 直接大循环

阴影采样代码 ,利用buffer数据 逆向计算出原始深度

shadowmap的精度是有2个维度的,一个是表现在shadowmap贴图尺寸上精度,也就是灯光空间的xy方向.一个是z方向也就是每个纹素的深度精度,上面说的 都是后者的改善.但前者的改善也很关键.
我们当然不是说简单的用更大尺寸的shadowmap,而是说如何在同一尺寸下提高精度,思路也很简单尽量的铺满他.
可以看到 这种倾斜的平行光,会在相机纵向方向上有很大一片面积没有内容,这样会让精度丢失 调整 aspect参数 匹配角度即可 .


调整前后对比效果 同样bias和normalbias参数


上面这张图提到 既然切块可以让局部的深度范围更小,深度数据更精确.那么实际工程中,就把他做到极限,每个像素都切.因为这些位置存在线性等比关系.所以 做下空间转换就能获得深度转换.视频可以看到
红色线段是 在大的灯光相机内深度.蓝色线段是场景包围盒相机的深度.可以看到同一个像素的2个极限.一个是[0.3,0.5],一个是[0,1]显然后者的精度提高了5倍.

 倾斜相机与正上方相深度演示https://www.zhihu.com/video/1469320348630347776
倾斜相机与正上方相深度演示https://www.zhihu.com/video/1469320348630347776
?新房入住添置家居物件,本质上就是一个家居细节优化的过程。
本期我们就来盘点一下,整个家优化过程中,最重要的10个物件添置,都不算贵,但却能大大提升生活品质。
小厨房、台面小,几乎是现代厨房的通病了。一般6平米的厨房,台面给小家电分一点、给水槽分一点。给燃气灶分一点,最后剩下的备菜区,就只有区区1米左右,非常局促。

切个菜案板就占掉台面一大半,剩下真没多少空间去放备菜。这时候就可以像上图一样,给墙面再增加一个备菜区,就能缓解台面空间不足的压力了。

实现过程很简单,就是入手一个可折叠的三角支架再去定一块亚克力板、或者是木板都行,然后把板子用免钉胶固定在三角支架上,把三角支架固定在墙面即可。

就能造一个可随时根据需求,折叠开合的备菜区。整个预算不到百元,就能一定程度上,解决台面小的这个共同的痛点。
空气炸烤箱,是去年才出来的新的电器品种,简单理解就是同时具备烤箱和空气炸锅的功能。

以前我因为工作忙,几乎没有时间自己下厨,可疫情在家,倒是让人有时间去折腾这些了。

空气炸锅功能去炸薯条、莲菜盒子……等等,相较真炸没有那么多油,健康。

烤箱功能则可以去烤个蛋挞、烤个菜、烤个红薯之类的,倒是真真切切让我感受到了什么才是生活的幸福,所以如果有机会,还是给家里添置一个这类东西。
我入手的是柏翠空气炸烤箱,相较单独的烤箱、空气炸锅可能没有那么强性能,可好处就是省空间,而且功能都能实现,我们平时做的那些东西,也能准确的做出来。柏翠这个算是在同品质下,性价比很高的款了,可入手。
给玄关增加这个小山丘感应灯,你会get两种乐趣。

其一是进门的仪式感:人踏入屋子,灯光亮起,提供照明的同时,还有点意思,像极了家在对你说:欢迎回来。

其二是来自美的震撼:在见到这个小山丘的感应灯之前,我从来没有想过一个感应灯竟然可以美到像艺术灯具那般。
然而,不像家里其他部分的灯光要花费大把预算,大量心血去设计协调,才能有美的效果。这个感应灯是充电款的,不用布线就能装在家里任何角落,怎么装怎么美,还省钱。
我家的玄关,就是如下图,一个长长的走道,做了柜子之后,更显窄,感觉怎么都选不到一个合适的换鞋凳,所以每次换鞋都跟在练武功似的。

后来,机缘巧合下就看到了这个看门狗造型的换鞋凳,因为造型不那么像换鞋凳,也比较轻,可随处挪动,即使是窄玄关,也不会太显得玄关小,自此之后,就再也不用金鸡独立,去穿鞋了。

而且颜值还很高,寓意“看门狗”,小孩还能拿来当玩具。
桌布,从实际用途上来讲,就是保护桌子,避免油污沾染。

但我们入手它可能并不是为了这,更多的是为了,时间久了可以通过改变桌布,来给家里带点新气象。
目前颜值高且服帖的就是这种皮质的桌布了。

可以照着桌子裁剪,能完全跟桌子贴合,会让人有种换了个新桌子的感觉。
不用我多讲,大家都熟悉买水送的饮水机是什么样子,严重拉低自家颜值。

所以,我的第一建议是:入手一个如上图的魔凡即热饮水机吧。
其实还有一种高颜值的饮水方式的存在,就是中央净水+管线机,其实就是自己家里的净水设备输出到管线机上,管线机跟是一个即热装置。
由于整体造价、后期的耗材成本都比较高(比订桶装水贵),

所以,普通家庭,我还是觉得,颜值较高,性价比也比较高的魔凡比较合适。
水桶藏在机身里,换水也比那种抗到饮水机上面的方便。

除此之外,还是一个有多档调节的即热热水器,无论是老爸泡茶的80°,小朋友冲奶的40°,成年人喝的60°开水,一共有6档调温,做到一键出热水,非常方便。
出水口的水龙头,还是可升降的,可以根据杯子的高度进行灵活调节,避免水溅出。
现在的我就趴在上面写东西,我家倒也是有书桌,但那个房间稍微有点冷。

这也是我一开始入手这个东西的初衷,在客厅临时办公用,平放斜放都没有问题,因为有吸力,还可直接放ipad。
但越用越久这个东西的用途也发生了变化,我家小孩用它来当餐桌,因为他不爱坐餐椅,所以每次吃饭都是沙发+小边几。

因为可调整高度,有一天我就把这东西拿到卧室去用,于是,我从沙发上,也懒到了床上,偶尔还在我是躺床上,把ipad、笔记本放旁边。
如果你我是有个沙发、飘窗,我相信很快这个地方就变成了衣服山。导致家里的整洁程度永远不在线。

所以,与其让飘窗沙发这些值钱的物件当脏衣篮,不如入手个隔夜衣架,回家不想洗的次净衣、睡衣均可以直接挂在上面,底部还能放一些杂七杂八的东西,如包包啊袜子之类的。
当然它不仅能用在卧室、玄关、客厅甚至卫生间也可用。
要说卫生间,从一开始入住至今,我觉得做得最成功的一次优化,一定是这个清洁工具上墙的方案。
墙面的位置选在卫生间的门后,存在感很低,而且因为上墙也更省空间,地面也能减少堆积,找清洁工具还一目了然。

布置起来很简单,核心就是一个拖把挂钩,现成的工具就能挂上去了。
如果是新入住的家庭,还没有清洁工具,注意一下颜色,统一选成白色,挂在墙上更显整洁。
要说最直接能关乎到幸福感的就是智能马桶盖了。

其实哪怕是最简单的座圈加热功能,都能给你带来很大程度上的体验提升,再者就是pp冲洗之类的,自动开合之类的功能,我一开始也觉得不可思议。
但真的是越用越觉得好,所以尽可能地给家里添置这个东西

pearson系数可以看作是去中心化之后的余弦相似度。
cos=nn.CosineSimilarity(dim=1, eps=1e-6)
pearson=cos(x1 - x1.mean(dim=1, keepdim=True), x2 - x2.mean(dim=1, keepdim=True))
对于nn而言,如果要使用pearson 作为loss function,这么计算就可以了。
对于lgb而言,需要计算grad和hessian
import torch
from torch import autograd
import numpy as np
y_pred=np.array([1.5,1.4,1.3,1.2,1.4])
y_pred=torch.from_numpy(y_pred)
y_pred.requires_grad=True
y_true=np.array([1.2,1.3,1.2,1.1,1.5])
y_true=torch.from_numpy(y_true)
y_true.requires_grad=False
cos=nn.CosineSimilarity(dim=0, eps=1e-6)
pearson=cos(y_pred - y_pred.mean(), y_true - y_true.mean())
grad=torch.autograd.grad(pearson,y_pred,create_graph=True,retain_graph=True)[0]
hessian=torch.autograd.grad(grad,y_pred,grad_outputs=torch.ones(y_pred.shape), create_graph=False)[0]实际使用了一下,发现这个loss很不稳定,如果发现加入之后training效果变差,可以考虑直接把hessian用全1替代,即只使用1阶梯度来fit
“吹风了!吹风了!”
相信今天下午,很多人都被“新风”刷屏了。
7+3变成5+3
取消“中风险”区
轻易不搞全员核酸
不再熔断
不再判定密接的密接
加大“一刀切、层层加码”的整治力度
严禁随意静默管理、封校停课
这些话,让很多人看到了希望,也想到了之前的各种反面例证,甚至是自己遭遇过的困境,
颇有"久旱逢甘霖"之感。

就连资本市场都欢欣鼓舞。


在这个新的防控措施中,我格外关注的是这句话:
“各地各部门要不折不扣把各项优化措施落实到位。”
是的,吹风只是暖心,但执行才是关键。
很多荒唐的事儿,不是因为之前搞的过严,而是明明有法律在那,有的人却在乱搞。
而且是打着“为你好”的名义,让你难受的说不出话来。
我们可以通过下面这道题,去感受“理论”和“实践”的距离。

我们都说依法治国。
什么是法?
中国《突发事件应对法》第11条早已明确规定:
“采取的应对突发事件的措施......应当选择有利于最大程度地保护公民、法人和其他组织权益的措施。”
但在现实层面,不少地方是怎么做的呢——简单粗暴的静默,动辄十多轮的检测,不断突破法治底线和人伦底线,在群众路线上疯狂出轨。
给鱼做核酸,给煤矿做核酸。

年纪轻轻的学生,也是说开除就开除(现已纠正)。

更有甚者,甚至以征信、子女就业威胁之。
搞得周带鱼,黄安,老胡这些浓眉大眼的人都开始吹胡子瞪眼睛了。
不是没有法,而是法令不行,自己造法,随意执法。
这种扭曲的根源是什么?
说白了,就是不拿法当回事,而是见“风”使舵。
现在,一阵新风传来,我想后面,肯定会有所优化,有所调整,有所忌惮。
但我们为什么总是要依赖“风”,看“风”呢?
如果能够始终坚持“法度在前,人民至上”,又何须吹风?
之前,鄂尔多斯的通告刷屏,通观全文,没有华丽辞藻,也没有情绪铺陈。
无论是“坚持生命至上、救人为先”,还是明确市民的自救权和紧急避险权,更多的就是重申常识。
没有华丽辞藻,也没有情绪铺陈。
但能强调“以人为本”,“法律赋予你的权利”,本身就充满了力量。
当年商鞅去秦国的第一件事,就是徙木立信,告诉世人:
“在这个国家,法最大!”

因为法度彰显,秦国遂广纳天下良才,从最为弱小,到吞并六国。
因为法度彰显,今天的美国即便枪击案泛滥,流浪汉遍地,但依然能吸引着全世界的高端人才,商业精英。
“法治”这两个字,真的很重要!
希望这阵新风会是一场转变吧。
往往“静下来”很容易,但要让社会重新“活起来”,却要难上许多。
而后者,才是中国未来发展的关键,也是更为久远的“人民至上”。
-完-
激情点赞、深情关注
相信大家都见过下面这张数据库访问优化的漏斗法则图,此图展示了数据库层面的优化方向的核心方向:每条SQL尽量使用更少的资源、更充分的利用数据库整体的资源,例如:可以通过业务逻辑和索引优化减少磁盘扫描的数据行数,通过业务逻辑优化减少彼此网络间传输的数据量,通过将复杂的计算逻辑放在端上执行来减少数据库层面的CPU和内存开销,通过将数据均匀打散在更多资源+并行计算的能力来提升整体的性能。

从上到下每一层优化法则可以达到的优化效果越来越不明显,但是优化的代价反而越来越大,也就意味着数据库的优化就像学生时代做考题一样,也应该由易到难。数据库优化是方法问题,也是意识问题。遇到数据库性能问题时优先恢复服务的想法毋庸置疑,但还是应该先定位性能瓶颈再确定优化方法更为稳妥,如果一上来就扩容,甚至切换和重启,不仅会导致解决问题的耗时更长同时可能会引发二次故障。
单纯数据库层面的具体优化思路是一方面,实际项目中不仅需要进行数据库层面的优化,也需要有全链路优化的意识,业务和开发人员看到的性能问题往往只是交易耗时长、TPS和吞吐上不去,第一反应就是数据库性能有问题,全链路优化的意识此时就显得尤为重要。
作者:
vivo - 人工智能推荐团队:何鑫、李恒、周健、黄金宝
vivo 人工智能推荐算法团队在深耕业务同时,也在积极探索适用于搜索/广告/推荐大规模性稀疏性算法训练框架。分别探索了 tensornet/XDL/tfra 等框架及组件,这些框架组件在分布式、稀疏性功能上做了扩展,能够弥补 tensorflow 在搜索/广告/推荐大规模性稀疏性场景不足,但是在通用性、易用性以及功能特点上,这些框架存在各种不足。
DeepRec 是阿里巴巴集团提供的针对搜索、推荐、广告场景模型的训练/预测引擎,在分布式、图优化、算子、Runtime 等方面对稀疏模型进行了深度性能优化,提供了丰富的高维稀疏特征功能的支持。基于 DeepRec 进行模型迭代不仅能带来更好的业务效果,同时在 Training/Inference 性能有明显的性能提升。
作为 DeepRec 最早的一批社区用户,vivo 在 DeepRec 还是内部项目时,就与 DeepRec 开发者保持密切的合作。经过一年积累与打磨,DeepRec 赋能 vivo 各个业务增长,vivo 也作为 DeepRec 深度用户,将业务中的需求以及使用中的问题积极回馈到 DeepRec 开源社区。

vivo 人工智能推荐算法组的业务包含了信息流、视频、音乐、广告等搜索/广告/推荐各类业务,基本涵盖了搜广推各类型的业务。

为了支撑上述场景的算法开发上线,vivo 自研了集特征数据、模型开发、模型推理等流程于一体的推荐服务平台。通过成熟、规范的推荐组件及服务,该平台为 vivo 内各推荐业务(广告、信息流等)提供一站式的推荐解决方案,便于业务快速构建推荐服务及算法策略高效迭代。

3.1.1 痛点
在实际业务实践发现,TensorFlow 原生 Embedding Layer 存在以下问题:

1.静态 Embedding OOV 问题
在构建 Embedding Layer 的时候,TensorFlow 需要首先构建一个静态 shape[Vocab_size, Embedding size ]的 Variable,然后利用 Lookup 的算子将特征值的 Embedding 向量查询出。在增量或者流式训练中,会出现 OOV 的问题。
2. 静态 Embedding hash 特征冲突
为了规避上述的 OOV 问题,通常做法是将特征值 hash 到一定的范围,但是又会引入 hash 冲突的问题,导致不同的特征值共用同一个 Embedding,会造成信息丢失,对模型训练是有损的。
3. 静态 Embedding 内存浪费
为了缓解 hash 冲突,通常会设置比真实的特征值个数 N 大一到两倍的 hash 范围,而这又会强行地增加模型的体积。
4. 低频特征冗余
在引入稀疏特征时,出现频次较低以及许久未出现的特征 ID 对于模型而言是冗余的。此外,交叉特征占据了大量的存储,可以在不影响训练效果的前提下过滤掉这些特征 ID。因此,迫切需求特征淘汰以及准入机制。
总的来讲,TensorFlow 的 Embedding Layer 对真实的业务场景有几个不太友好的点,第一是可拓展性差,第二是 hash 冲突导致模型训练有损,第三是无法处理冗余的稀疏特征。而 DeepRec 巧妙地解决了上述问题,主要提供了基于 Embedding Variable 的动态 Embeeding 功能和特征准入/淘汰功能。
3.1.2 Embedding Variable

DeepRec 中的 EmbeddingVariable 以 HashTable 作为内部存储的基本结构,动态的创建/释放 Embedding 向量,适配了 Embedding 前向查询,反向更新等 OP,从而解决了用户的痛点。
在构建 Embedding Layer 时使用 DeepRec的Embedding Variable。利用 Embedding Variable 具有动态维度的特性,模型训练对新增的特征值无感知。此外,由于摒弃了 hash 的操作,训练的模型也是无损的,同时模型的体积也会缩小。
3.1.3 特征准入/淘汰
1. 特征准入:
DeepRec 提供了基于 BloomFilter 和 Counter 两种策略的准入机制。特征准入可以避免模型稀疏特征的快速增长,拒绝低频特征进入模型,影响模型收敛效果。
2. 特征淘汰:
DeepRec 支持两种淘汰策略,一种是按照 global step 进行淘汰,一种是按照 L2 weight 进行淘汰,它们将不符合规则的特征从模型参数中剔除,保证特征的有效性。
3.1.4 收益
1. 静态 Embedding 升级到动态 Embedding
使用 DeepRec 的动态 Eembedding 替换 TensorFlow 的静态 Embedding 后,保证所有特征 Embedding 无冲突,离线auc提升 0.5%,线上点击率提升 1.2%,同时模型体积缩小 20%。
2. ID 特征的利用
在使用 TensorFlow 时,vivo 尝试过对 ID 特征进行 hash 处理输入模型,实验表明这种操作对比基线具有负收益。这是由于 ID 特征过于稀疏,同时 ID 具有唯一指示性,hash 处理会带来大量的 Embedding 冲突。基于动态 Embedding,使用 ID 特征离线 auc 提升 0.4%,线上点击率提升 1%;同时配合 global step 特征淘汰,离线 auc 提升 0.2%,线上点击率提升 0.5%。
3.2.1 痛点
目前 vivo 内部使用的是 TFRecord 数据格式存储训练数据,这种存储格式存在以下缺陷:
1. 占用存储空间大
由于 TFRecord 采用 protocol buffer 结构化数据存储,存储不够紧凑,占用空间比较大,在训练时 I/O 开销也非常大。vivo 尝试过利用 prebatch 的方式存储 TFRecord 以节省存储空间,但是此方案解析相对复杂,I/O 开销进一步加剧。
2. 非明文存储
由于 TFRecord 以二进制格式存储,无法直接查看数据内容,存在解析困难、不便进行数据分析的问题。
3.2.2 Parquet Dataset
Parquet 是一种列式存储的数据格式,能够节省存储资源,加快数据读取速度。DeepRec 的 Parquet Dataset 支持读取 Parquet 文件,开箱即用,无需额外安装第三库,使用简单方便。同时,Parquet Dataset 能够加快数据读取速度,提高模型训练的 I/O 性能。
3.2.3 收益
vivo 内部尝试使用 Parquet Dataset 来替换现有 TFRecord,提高训练速度 30%,减少样本存储成本 38%,降低带宽成本。同时,vivo 内部支持 hive 查询 Parquet 文件,算法工程师能够高效快捷地分析样本数据。
在业务逐渐发展过程中,广告召回量增长 3.5 倍,同时目标预估数增加两倍,推理计算复杂度增加,超时率超过 5%,严重影响线上服务可用性以及业务指标。因此,vivo 尝试探索升级改造现有推理服务,保证业务可持续发展。vivo 借助 DeepRec 开源的诸多推理优化功能,在 CPU 推理改造以及 GPU 推理升级方面进行探索,并取得一定收益。
vivo 直接使用 TensorFlow 提供的 C++ 接口调用 Session::Run,无法实现多 Session 并发处理 Request,导致单 Session 无法实现 CPU 的有效利用。如果通过多 Instance 方式(多进程),无法共享底层的 Variable,导致大量使用内存,并且每个 Instance 各自加载一遍模型,严重影响资源的使用率和模型加载效率。为了提高 CPU 使用率,也尝试多组 Session Intra/Inter,均会导致 latency升高,服务可用性降低。
基于 ShareNothing 架构的 SessionGroup
DeepRec 提供的 SessionGroup 能够有效地解决上述问题,其基本架构如下图所示:

SessionGroup 可配置一组 Session,并且通过 Round Robin (支持用户自定义策略)方式将用户请求分发到某一个 Session。SessionGroup 对不同 Session 之间的资源进行隔离,每个 Session 拥有私有的线程池,并且支持每个线程池绑定底层的 CPU Core(numa-aware),可以最大程度地避免共享资源导致的锁冲突开销。SessionGroup 中唯一共享的资源是 Variable,所有 Session 共享底层的 Variable,并且模型加载只需要加载一次。
在使用 SessionGroup 功能后,CPU 使用率低的问题明显得到缓解,在保证 latency 的前提下极大提高 QPS,单机 QPS 提升高达 80%,单机 CPU 利用率提升 75%。
经过 SessionGroup 的优化,虽然 CPU 推理性能得到改善,但是超时率依旧无法得到缓解。由于以下几点原因,vivo 尝试探索 GPU 推理来优化线上性能。
1. 多目标模型目标塔数较多
2. 模型中使用 Attention、LayerNorm、GateNet 等复杂结构
3. 特征多,存在大量稀疏特征
4.2.1 Device Placement Optimization
通常,对于稀疏特征的处理一般是将其 Embedding 化,由于模型中存在大量的稀疏特征,因此 vivo 的广告模型使用大量的 Embedding 算子。从推理的 timeline 可以看出,Embedding 算子分散在 timeline 的各个阶段,导致大量的 GPU kernel launch 以及数据拷贝,因此图计算非常耗时。

Device Placement Optimization 完全将 Embedding Layer placed 到 CPU 上,解决Embedding layer 内部存在的 CPU 和 GPU 之间大量数据拷贝问题。

Device Placement Optimization 性能优化明显,CPU 算子(主要是 Embedding Layer)的计算集中在 timeline 的最开端,之后 GPU 主要负责网络层的计算。相较于 CPU 推理,Device Placement Optimization P99 降低 35%。
4.2.2 CUDA Multi-Stream 功能
在推理过程中,vivo 发现 GPU 利用率低,GPU 算力浪费。DeepRec 支持用户使用 multi-stream 功能,多 stream 并发计算,提升 GPU 利用率。多线程并发 launch kernel 时,存在较大的锁开销,极大影响了 kernel launch 的效率,这里的锁与 CUDA Driver 中 Context 相关。因此可以通过使用 MPS/Multi-context 来避免 launch 过程中锁开销,从而进一步提升 GPU 有效利用率。

此外,模型中存在大量的 H2D 以及 D2H 的数据拷贝,在原生代码中,计算 stream 和拷贝 stream 是独立的,这会导致 stream 之间存在大量同步开销,同时对于在 Recv 算子之后的计算算子,必须等到 MemCopy 完成之后才能被 launch 执行,MemCopy 和 launch 难以 overlap 执行。基于以上问题,NV 专家计算团队的同学在 multi-stream 功能基础上进一步优化,开发了 MergeStream 功能,允许 MemCopy 和计算使用相同的 stream,从而减少上述的同步开销以及允许 Recv 之后计算算子 launch 开销被 overlap。

vivo 在线上推理服务中使用了 multi-stream 功能,P99 降低 18%。更进一步地,在使用 merge stream 功能后,P99 降低 11%。
4.2.3 编译优化-BladeDISC
BladeDISC 是阿里集团自主研发的、原生支持存在动态尺寸模型的深度学习编译器。DeepRec 中集成了 BladeDISC,通过使用 BladeDISC 内置的 aStitch 大尺度算子融合技术对于存在较多访存密集型算子的模型有显著的效果。利用 BladeDISC 对模型进行编译优化,推理性能得到大幅度提升。
BladeDISC 将大量访存密集型算子编译成一个大的融合算子,可以大大减少框架调度和 kernel launch 的开销。区别于其他深度学习编译器的是,BladeDISC 还会通过优化 GPU 不同层次存储(特别是 SharedMemory)的使用来提升了访存操作和 Op 间数据交换的性能。图中可以看到,绿色是 Blade DISC 优化合并的算子替代了原图中大量的算子。


另外,由于线上模型比较复杂,为了进一步减少编译耗时、提升部署效率,vivo 启用了 BladeDISC 的编译缓存功能。开启此功能时,BladeDISC 仅会在新旧版本模型的 Graph 结构发生改变时触发编译,如果新旧模型仅有权重变更则复用之前的编译结果。经过验证,编译缓存在保证正确性的同时,几乎掩盖了编译模型的开销,模型更新速度与之前几乎相同。在使用 BladeDISC 功能后,线上服务 P99 降低 21%。
4.2.4 总结
DeepRec 提供大量的解决方案可以帮助用户快速实施 GPU 推理。经过一系列优化,相较于 CPU 推理,GPU 推理 P99 降低 50%,GPU 利用率平均在 60% 以上。此外,线上一张英伟达 T4 显卡的推理性能超过两台 CPU 机器,节省了大量的机器资源,机器成本降低 60%。
基于 CPU 的分布式异步训练存在两个问题:一是异步训练会损失训练精度,模型难以收敛到最佳;二是随着模型结构逐渐复杂,训练性能会急剧下降。未来,vivo 打算尝试基于 GPU 的同步训练来加速复杂模型训练。DeepRec 支持两种 GPU 同步框架——SparseOperationKit(SOK)和HybridBackend。后续 vivo 将尝试这两种 GPU 同步训练来加速模型训练。
DeepRec开源地址:https://github.com/alibaba/Deep
最佳版本请看原博客:
Google新搜出的优化器Lion:效率与效果兼得的“训练狮” - 科学空间|Scientific Spaces昨天在Arixv上发现了Google新发的一篇论文《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。
本文主要关心搜索出来的优化器本身,所以关于搜索过程的细节就不讨论了,对此有兴趣读者自行看原论文就好。Lion优化器的更新过程为
其中
是损失函数的梯度,
是符号函数,即正数变为1、负数变为-1。我们可以对比一下目前的主流优化器AdamW的更新过程
对比很明显,Lion相比AdamW参数更少(少了个),少缓存了一组参数
(所以更省显存),并且去掉了AdamW更新过程中计算量最大的除法和开根号运算(所以更快)。
在此之前,跟Lion最相似的优化器应该是SIGNUM,其更新过程为
跟Lion一样,SIGNUM也用到了符号函数处理更新量,而且比Lion更加简化(等价于Lion在和
的特例),但是很遗憾,SIGNUM并没有取得更好的效果,它的设计初衷只是降低分布式计算中的传输成本。Lion的更新规则有所不同,尤其是动量的更新放在了变量的更新之后,并且在充分的实验中显示出了它在效果上的优势。
本文开头就说了,Lion在相当多的任务上都做了实验,实验结果很多,下面罗列一些笔者认为比较关键的结果。





看到论文效果如此惊人,笔者也跃跃欲试。在跑实验之前,自然需要了解一下各个超参的设置。首先是,原论文自动搜索出来的结果是
,并在大部分实验中复用了这个组合,但是在NLP的任务上则使用了
这个组合(论文的详细实验配置在最后一页的Table 12)。
比较关键的学习率和权重衰减率
,由于Lion的更新量
每个分量的绝对值都是1,这通常比AdamW要大,所以学习率要缩小10倍以上,才能获得大致相同的更新幅度;而由于学习率降低了,那么为了使权重衰减的幅度保持不变,权重衰减率应该要放大相应的倍数。原论文的最后一页给出了各个实验的超参数参考值,其中小模型(Base级别)上使用的是
和
,大模型(参数10亿以上)则适当降低了学习率到
甚至
。
事实上,之前我们在《基于Amos优化器思想推导出来的一些“炼丹策略”》就推导过学习率和权重衰减率的一个组合方案,参考这个方案来设置是最方便的。在该方案中,更新量写为(记号跟前面的描述略有不同,但不至于混淆,应该就不强行统一了)
其中
其中是原本的更新量;
是(初始阶段)参数变化的相对大小,一般是
级别,表示每步更新后参数模长的变化幅度大致是千分之一;
是一个超参数,没什么特殊情况可以设为1;
是控制学习率衰减速度的超参数,可以根据训练数据大小等设置。
由于经过了
运算,因此
,
是参数的维度;
,这我们在《基于Amos优化器思想推导出来的一些“炼丹策略”》已经推导过了,其中
是参数的变化尺度,对于乘性矩阵,
就是它的初始化方差。所以,经过一系列简化之后,有
这里的就是前面的
,而
。按照BERT base的
来算,初始化方差的量级大致在
左右,于是
,假设
取
(为了给结果凑个整),那么按照上式学习率大约是
、衰减率大约是
。在笔者自己的MLM预训练实验中,选取这两个组合效果比较好。
个人实现:https://github.com/bojone/bert4keras
总体来看,Lion表现可圈可点,不管是原论文还是笔者自己的实验中,跟AdamW相比都有一战之力,再加上Lion更快以及更省显存的特点,或者可以预见未来的主流优化器将有它的一席之地。
自Adam提出以来,由于其快速收敛的特性成为了很多模型的默认优化器。甚至有学者提出,这个现象将反过来导致一个进化效应:所有的模型改进都在往Adam有利的方向发展,换句话说,由于我们选择了Adam作为优化器,那么就有可能将很多实际有效、但是在Adam优化器上无效的改动都抛弃了,剩下的都是对Adam有利的改进,详细的评价可以参考《NEURAL NETWORKS (MAYBE) EVOLVED TO MAKE ADAM THE BEST OPTIMIZER》。所以,在此大背景之下,能够发现比Adam更简单且更有效的优化器,是一件很了不起的事情,哪怕它是借助大量算力搜索出来的。
可能读者会有疑问:Lion凭啥可以取得更好的泛化性能呢?原论文的解释是这个操作引入了额外的噪声(相比于准确的浮点值),它使得模型进入了Loss更平坦(但未必更小)的区域,从而泛化性能更好。为了验证这一点,作者比较了AdamW和Lion训练出来的模型权重的抗干扰能力,结果显示Lion的抗干扰能力更好。然而,理论上来说,这只能证明Lion确实进入到了更平坦的区域,但无法证明该结果是
操作造成的。不过,Adam发表这么多年了,关于它的机理也还没有彻底研究清楚,而Lion只是刚刚提出,就不必过于吹毛求疵了。
笔者的猜测是,Lion通过操作平等地对待了每一个分量,使得模型充分地发挥了每一个分量的作用,从而有更好的泛化性能。如果是SGD,那么更新的大小正比于它的梯度,然而有些分量梯度小,可能仅仅是因为它没初始化好,而并非它不重要,所以Lion的
操作算是为每个参数都提供了“恢复活力”甚至“再创辉煌”的机会。事实上可以证明,Adam早期的更新量也接近于
,只是随着训练步数的增加才逐渐偏离。
Lion是不是足够完美呢?显然不是,比如原论文就指出它在小batch_size(小于64)的时候效果不如AdamW,这也不难理解,本来已经带来了噪声,而小batch_size则进一步增加了噪声,噪声这个东西,必须适量才好,所以两者叠加之下,很可能有噪声过量导致效果恶化。另外,也正因为
加剧了优化过程的噪声,所以参数设置不当时容易出现损失变大等发散情况,这时候可以尝试引入Warmup,或者增加Warmup步数。还有,Lion依旧需要缓存动量参数,所以它的显存占用多于AdaFactor,能不能进一步优化这部分参数量呢?暂时还不得而知。
本文介绍了Google新提出的优化器Lion,它通过大量算力搜索并结合人工干预得出,相比主流的AdamW,有着速度更快且更省内存的特点,并且大量实验结果显示,它在多数任务上都有着不逊色于甚至优于AdamW的表现。
随着大模型被越来越多的应用到不同的领域,随之而来的问题是应用过程中的推理优化问题,针对LLM推理性能优化有一些新的方向,最近一直在学习和研究,今天简单总结下学习笔记。
PART01:自回归场景引发的KVCache问题
首先LLM推理的过程是一个自回归的过程,也就是说前i次的token会作为第i+1次的预测数据送入模型,拿到第i+1次的推理token。在这个过程中Transformer会执行自注意力操作,为此需要给当前序列中的每个项目(无论是prompt/context还是生成的token)提取键值(kv)向量。这些向量存储在一个矩阵中,通常被称为kv cache。kv cache是为了避免每次采样token时重新计算键值向量。利用预先计算好的k值和v值,可以节省大量计算时间,尽管这会占用一定的存储空间。

所以未来LLM推理优化的方案就比较清晰了,就是尽可能的减少推理过程中kv键值对的重复计算,实现kv cache的优化。目前减少KV cache的手段有许多,比如page attention、MQA、MGA等,另外flash attention可以通过硬件内存使用的优化,提升推理性能。
PART02:PageAttention显存优化
PageAttention是目前kv cache优化的重要技术手段,目前最炙手可热的大模型推理加速项目VLLM的核心就是PageAttention技术。在缓存中,这些 KV cache 都很大,并且大小是动态变化的,难以预测。已有的系统中,由于显存碎片和过度预留,浪费了60%-80%的显存。PageAttention提供了一种技术手段解决显存碎片化的问题,从而可以减少显存占用,提高KV cache可使用的显存空间,提升推理性能。
首先,PageAttention命名的灵感来自OS系统中虚拟内存和分页的思想。可以实现在不连续的空间存储连续的kv键值。

另外,因为所有键值都是分布存储的,需要通过分页管理彼此的关系。序列的连续逻辑块通过 block table 映射到非连续物理块。

另外,同一个prompt生成多个输出序列,可以共享计算过程中的attention键值,实现copy-on-write机制,即只有需要修改的时候才会复制,从而大大降低显存占用。

PART03:MHA\\GQA\\MQA优化技术
接下来是GQA和MQA优化技术,在LLAMA2的论文中,提到了相关技术用来做推理优化,目前GQA和MQA也是许多大模型推理研究机构核心探索的方向。
MQA,全称 Multi Query Attention, 而 GQA 则是前段时间 Google 提出的 MQA 变种,全称 Group-Query Attention。MHA(Multi-head Attention)是标准的多头注意力机制,h个Query、Key 和 Value 矩阵。MQA 让所有的头之间共享同一份 Key 和 Value 矩阵,每个头只单独保留了一份 Query 参数,从而大大减少 Key 和 Value 矩阵的参数量。GQA将查询头分成N组,每个组共享一个Key 和 Value 矩阵

如上图,GQA以及MQA都可以实现一定程度的Key value的共享,从而可以使模型体积减小,GQA是MQA和MHA的折中方案。这两种技术的加速原理是(1)减少了数据的读取(2)减少了推理过程中的KV Cache。需要注意的是GQA和MQA需要在模型训练的时候开启,按照相应的模式生成模型。
PART04:FlashAttention优化技术
最后讲下Flash attention优化技术,Flash attention推理加速技术是利用GPU硬件非均匀的存储器层次结构实现内存节省和推理加速,它的论文标题是“FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”。意思是通过合理的应用GPU显存实现IO的优化,从而提升资源利用率,提高性能。

首先我们要了解一个硬件机制,计算速度越快的硬件往往越昂贵且体积越小,Flash attention的核心原理是尽可能地合理应用SRAM内存计算资源。
A100 GPU有40-80GB的高带宽内存(HBM),带宽为1.5-2.0 TB/s,而每108个流处理器有192KB的SRAM,带宽估计在19TB/s左右。也就是说,存在一种优化方案是利用SRAM远快于HBM的性能优势,将密集计算尽放在SRAM,减少与HBM的反复通信,实现整体的IO效率最大化。比如可以将矩阵计算过程,softmax函数尽可能在SRAM中处理并保留中间结果,全部计算完成后再写回HBM,这样就可以减少HBM的写入写出频次,从而提升整体的计算性能。如何有效分割矩阵的计算过程,涉及到flash attention的核心计算逻辑Tiling算法,这部分在论文中也有详细的介绍。
以上是对于最近LLM模型推理优化方面新的一些技术点的学习和概况总结,感激引用的文章作者,这方面还有很多内容需要总结和进一步消化。
引用:
[1]https://zhuanlan.zhihu.com/p/642802585
[2]https://baijiahao.baidu.com/s?id=1763480207227229622&wfr=spider&for=pc
[3]http://lihuaxi.xjx100.cn/news/1335720.html?action=onClick
[4]https://zhuanlan.zhihu.com/p/647130255
[5]https://baijiahao.baidu.com/s?id=1774803715921029316&wfr=spider&for=pc
[6]https://zhuanlan.zhihu.com/p/645376942

